SAP社 및 HANA 소개
SAP HANA 소개
- SAP社는
IBM의 AI 부서의 5명의 엔지니어는 IBM을 퇴사하고 1972년 6월에 설립했습니다.
SAP의 첫번째 고객은 Imperial 화학회사의 독일지사입니다.. 이것은 IBM의 메인프레임기반에서 개발된 인사와 회계 프로그램으로 이때 소프트웨어가 Real time(실시간)으로 구현되었다고 해서 R를 붙이게 되었다. 여기서 R은 Real time , 2는 2 Tier in Client Server Architecture 이다.
1973년에 SAP R/98이란 화학회사용 제품이 출시하게 되었다.
1976년 SAP 법인을 설립하고 본사를 독일 발도프로 옮겼다.그리고 3년후인 1979년에 자재관리와생산관리를 확장한 SAP R/2를 발표하게 됩니다.
계속해서 SAP R2를 1991년까지 사용하다가 1992년에 새로운 버전인 SAP R/3 제품을 발표합니다.
메인프레임 기반의 호스트 환경의 R2에서 클라이언트 서버환경 기반으로 하는 R3 제품을 출시하게 되었다. 3는 3 Tier in Client Server Architecture 이다.
SAP는 1990년 후반부터 불어 닦친 인터넷 열풍에 따라 mySAP.com 으로 디자인한 인터넷 기반 비즈니스 소프트웨어를 개발하게 됩니다.
2005년에 회사의 공식 이름인 SAP AG가 되었습니다. 여기어 AG는 Aktiengesellschaft 약자로 주식회사( public limited company)입니다.
출처: Wikipedia
- SAP HANA는
HANA는 하나는 ‘하소 플래트너의 새 구조’(Hasso Plattner's New Architecture)라는 뜻이다.또 High Performance ANalytic Appliance의 약어 등으로 알려졌다. 하지만 차 교수는 “하나”는 한국어로 DB와 처리장치를 하나로 합쳤다는 뜻도 있다며 제품명 후보 가운데 ‘하나”를 지지했다고 합니다. 2000년 차상균 서울대학교 전기컴퓨터공학부 교수가 제자들과 함께 설립한 TIM(Transact in Memory, Inc.)에서 개발을 시작했다. 그러나 국내 투자자를 구하지 못해 2002년 미국 실리콘밸리 멘로파크에 미국법인을 세웠고 2005년 SAP가 당시 Database분야 세계 1위였던 오라클과 경쟁하는 중에 TIM의 가능성을 보고 인수하면서, 서울대 연구소는 SAP 한국연구소가 되었다. 이후 6년간 개발을 계속하여 2011년 6월 출시되었다.
SAP HANA의 DATABASE 관점에서 먼저 보고 그 다음으로 전체적인 SAP 제품에서 SAP HANA의 위치와 DB 시장의 1위인 오라클 DB와 경쟁에서 얼마나 SAP 제품에서 DB를 HAHA로 사용 할 것인가가 저를 포함한 SAP 제품을 사용하고 있는 분들에게 관심사 일거라 생각합니다. 이부분은 천천히 언급하도록 하겠습니다.
오라클 DB같은 전통적인 Database들은 모든 DATA를 Disk에 저장하고 사용자가 DATA를 요청하면 메모리에 필요한 DATA를 가져와서 사용하게 되어 있는 구조입니다.
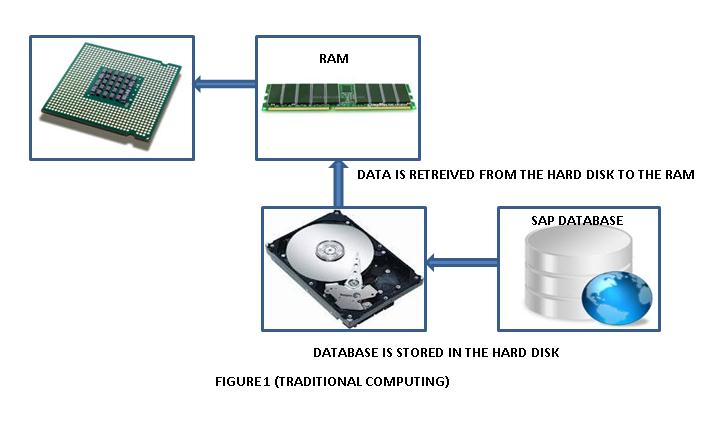
이것은 IT를 하시지 않는 분들에게 이해하기 어려운 부분이 있어서 간단하게 설명하도록 하겠습니다.

여학생이 책상에서 기말 시험을 본다고 생각하겠습니다.공부를 필요한 과목들 수학,영어,국어,역사,사회,과학 책으로 공부한다고 했을 때 수학공부를 하면 책장에서 수학책을 꺼내서 공부하고 수학공부가 끝나면 수학책을 책장에 넣어놓고 영어 공부를 위해 영어책을 꺼내는 것을 전통적인 DATABASE 구조입니다.
즉 책장은 디스크(DISK)이고, 수학책은 데이터(DATA), 책상은 메모리(Memory), 사람의 머리는 중앙처리장치(CPU)입니다.
전통적인 DB는 책장(DISK)에서 필요한 책(DATA)를 책상(Memory)에 올려놓고 머리(CPU)로 공부는그런 구조입니다.
수학책으로 책상에 올려놓고 공부하다 수학공부를 끝내면 책장에 꽂아두고, 다시 영어책을 책상에 꺼내놓고 공부하는 그런 방식이 전통적인 DATABASE 구조입니다.
책상(Memory)의 공간이 한정되어 있기 때문에 수학책(DATA), 영어책, 국어책,사회책등 모든 책들을 책상에 모두 다 올려 놓을 수 없어서 공부를 마친 수학책(DATA)은 다시 책장(DISK)에 꽂아 두게 됩니다.
SAP HANA는 책을 놓고 공부하는 곳인 책상(Memory)를 공부에 필요한 책(DATA)를 모두 놓고도 남을 큰 책상을 만들는 것입니다. 그렇게 되면 수학책(DATA)를 다시 책장(DISK)에 꽂아 놓을 필요 없게 되고 공부를 하는 속도(DATA 처리속도)도 빠르게 됩니다.
먼저 SAP HANA는 인메모리 데이타베이스(In-memory Databbase)입니다.
- 하드웨어와 소프트웨어가 결합하여 실시간으로 대량의 데이터를 메모리에서 처리합니다.
- 행(Column=세로줄)과 열(Row=가로줄)을 혼합하여 사용하는 Database 기술입니다.
- DATA는 디스크에 존재하지 않고 메모리 안에(In-Memory)에 존재합니다.
- 실시간으로 분석하고 개발하기에 적합한 Database입니다
댓글 3개
사고력수학
I truly love your blog.. Great colors & theme. Did you create this amazing site yourself?
Please reply back as I’m trying to create my own website and
would love to find out where you got this from or
what the theme is named. Thank you!
Maxwell Shollenberger
I was very pleased to uncover this web site. I wanted to thank you for your time for this particularly fantastic read!!
박성두
I thank you for your attention.
I shall write a lot when i have free time during at work.